در این مطلب در مورد تنظیم یک ابزار Redis cluster در سیستم محلی صحبت میکنیم. اینکه مفهوم توزیع ذخیرهسازی در آن چگونه است و چگونه میتواند مشکلات کاربری و عملکردی را رفع کند. قبل از این که کار را شروع کنیم، بهتر است برخی مفاهیم را به صورت خلاصه در مورد Redis و ابزار Redis cluster بیان کنیم.

Redis چیست؟
۱) Redis یک منبع ذخیره داده در حافظه اصلی (in-memory) است.
حافظه اصلی یا in-memory: Redis دادهها را با الگوی کلید-مقدار در حافظه پنهان نگهداری میکند و آن را بر روی دیسک نمینویسد. چنین عملکردی باعث میشود که روند خواندن و نوشتن داده بسیار سریع باشد. البته گزینه نوشتن دادهها در دیسک برای Redis وجود دارد.
الگوی ذخیرهسازی کلید-مقدار: Redis میتواند دادهها را به صورت جفتهای کلید-مقدار ذخیره کند.
به عنوان مثال در عبارت SET “name” “Masoud”، کلید “name” و مقدار “Masoud” است.
۲) Redis پایگاه دادهای خارج از SQL است.
۳) تعامل با داده از طریق خط فرمان صورت میگیرد.
Redis به عنوان یک پایگاه داده
 دریافت داده از یک دیسک حافظه میتواند بسیار وقتگیر باشد. برای افزایش عملکرد سیستم، میتوانیم درخواستهایی را که به پاسخ سریع نیاز دارند، وارد حافظه Redis کنیم و در حالی که سایر بخشهای دادهها در پایگاه داده اصلی حفظ میکنیم، سرویسدهی را از آنجا انجام دهیم.
دریافت داده از یک دیسک حافظه میتواند بسیار وقتگیر باشد. برای افزایش عملکرد سیستم، میتوانیم درخواستهایی را که به پاسخ سریع نیاز دارند، وارد حافظه Redis کنیم و در حالی که سایر بخشهای دادهها در پایگاه داده اصلی حفظ میکنیم، سرویسدهی را از آنجا انجام دهیم.
نسخههای کپی اولیه و ثانویه Redis
Redis میتواند دادهها در چند پایگاه داده ثانویه تکرار کند. این نسخههای ثانویه، دارای کپی دقیقی از پایگاه داده اصلی خواهند بود. چنین واقعاً در بهینهسازی عملکرد مفید خواهد بود.
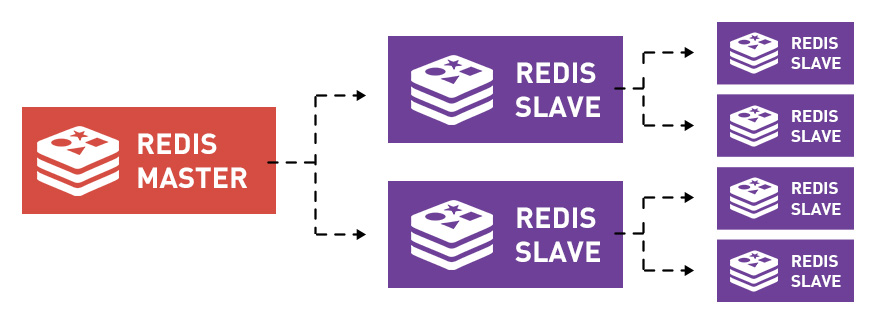
بر این اساس، شما میتوانید Redis را به عنوان یک پایگاه داده، یک حافظه نهان یا یک پیامنگار استفاده کنید. اگر برای اولین بار است که با نام Redis برخورد میکنید، شاید بهتر است که مقالات قبلی ما را نیز در این زمینه مطالعه کنید.
ابزار Redis cluster چیست؟
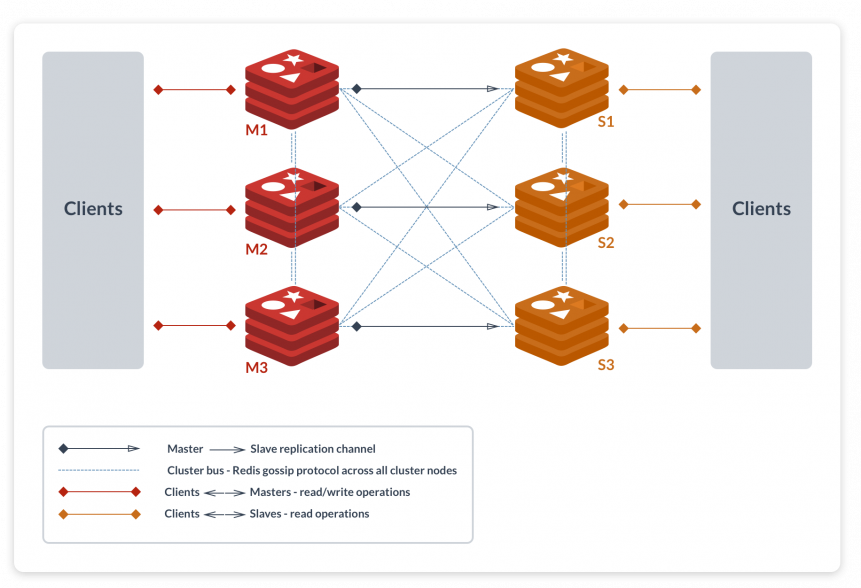
ساختار پیشفرض ابزار Redis cluster
ابزار Redis cluster در یک تعریف ساده، یک استراتژی شاردینگ یا طبقهبندی دادههاست. این ابزار به صورت اتوماتیک، دادهها را در سیستمهای چندگانه Redis تقسیمبندی میکند. در واقع Redis cluster یک نسخه پیشرفته از Redis محسوب میشود که به ذخیرههای گسترده دسترسی پیدا میکند و موجب جلوگیری از توقف عملکرد به علت مشکل در یک نقطه خاص شبکه میشود.
به طور خلاصه ابزار Redis cluster دارای ویژگیهای زیر است:
- مقیاسپذیر از نظر افقی: میتوانیم بنابر نیاز به ظرفیت بیشتر در شبکه، نقطه اضافه کنیم.ی
- شاردینگ داده اتوماتیک: میتواند به صورت اتوماتیک دادهها را بین نقاط مختلف پارتیشنبندی و جداسازی کند.
- تابآوری: حتی اگر یک نقطه از شبکه را از دست بدهیم، همچنان میتوانید بدون اینکه به دادهها آسیبی وارد شود، به عملکرد خود ادامه بدهیم.
- مدیریت غیرمتمرکز: هیچکدام از نقاط شبکه، عنصر وابسته به کل کلاستر نیست. هر کدام از نقاط در تنظیمات کلاستر مشارکت میکند (با استفاده از پروتکل gossip).
توپولوژی ابزار Redis cluster
حداقلهای موردنیاز برای کلاستر
- سه نقطه مستر یا اصلی Redis
- سه نقطه فرعی Redis، یکی برای هر نقطه اصلی
محل ذخیره گسترده برای ابزار Redis cluster
هر کلیدی که در Redis cluster ذخیره میکنید با یک hash slot همراه خواهد بود. بین 0 تا 16383 اسلات در یک Redis cluster وجود دارد. بنابراین، یک Redis cluster میتواند حداکثر ۱۶۳۸۴ نقطه اصلی داشته باشد. با این حال، توصیه میشود که تعداد را در حدّ هزار نقطه حفظ کنید. هر کدام از نقطههای اصلی یا مستر کنترل زیرمجموعهای شامل ۱۶۳۸۴ عدد hash slot را برعهده دارد.
الگوریتم توزیعی که Redis Cluster برای انتقال کلیدها به hash slot ها استفاده میکند، به صورت زیر است:
HASH_SLOT = CRC16(key) mod HASH_SLOTS_NUMBER
به عنوان مثال، فرض کنید که فضای کلید به ۱۰ اسلات (صفر تا ۹) تقسیم شده باشد. هر کدام از نقاط یک زیرمجموعه از hash slot ها را در بر خواهد داشت.
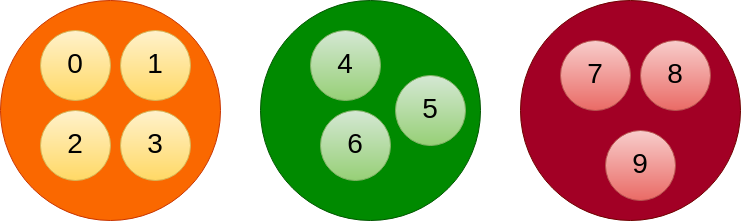
کلید “name” در اسلات به صورت زیر خواهد بود.
slot = CRC16(“name”) % 16384
مدیریت وقفهها در ابزار Redis Cluster
Redis به منظور افزایش دسترسی به دادهها، مفهوم اصلی-فرعی یا Master-Slave را معرفی کرده است. در نتیجه، وقفه در یک نقطه، باعث وقفه کل شبکه نمیشود. هر کدام از نقاط اصلی در یک Redis cluster حداقل یک نقطه فرعی دارد. وقتی عملکرد این نقطه اصلی متوقف شود یا دسترسی به آن غیرممکن گردد، کلاستر به صورت اتوماتیک، نقطه فرعی آن را برمیگزیند. در این حالت، این نقطه، نقطه مستر جدید خواهد بود. بنابراین، مشکل در یک نقطه، باعث توقف عملکرد کل سیستم نمیشود.
نحوه تشخیص مشکل و وقفه
هر کدام از نقاط دارای یک شناسه منحصر به فرد در کلاستر هستند. این شناسه برای تشخیص هر کدام از نقاط در سراسر کلاستر با استفاده از پروتکل gossip به کار میرود.
بنابراین، یک نقاط حاوی اطلاعات زیر خواهد بود.
- شناسه نقطه، آدرس IP و پورت
- یک سری علائم (flag)
- در صورتی که نقطه به صورت فرعی علامتگذاری شده باشد، نقطه اصلی آن مشخص است.
- آخرین باری که نقطه ping شده، چه زمانی بوده است.
- آخرین باری که pong دریافت شده، چه زمانی بوده است.
وقتی دستور ping را برای یک نقطه Redis اجرا میکنید، اگر عملکرد درستی داشته باشد، جواب را با یک pong میدهد.
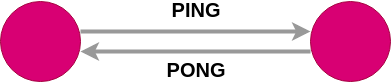
نقاط در یک کلاستر همیشه با هم ارتباط gossip دارند. در نتیجه، میتوانند به صورت اتوماتیک وضعیت نقاط دیگر را داشته باشند.
به عنوان مثال، اگر A با B ارتباط داشته باشد (B را بشناسد) و به همین ترتیب، B نیز با C در ارتباط باشد، معمولاً B پیام gossip در مورد C به نقطه A ارسال میکند. سپس A نقطه C را به عنوان بخشی از شبکه درنظر میگیرد و سعی میکند که با C ارتباط برقرار کند.
دو نوع شناسه یا flag برای تشخیص وقفه در سیستم استفاده میشوند؛ PFAIL و FAIL.
PFAIL (مشکل احتمالی): یک مشکل از نوع ناشناخته.
FAIL: این نوع شناسه به شما میگوید که یک نقطه در حالت توقف عملکرد است و این موضوع توسط اکثریت نقاط مستر در یک مدتزمان مشخص تأیید شده است.
ارتباط نقطه به نقطه از پروتکل باینری (Cluster Bus) پیروی میکند که از نظر سرعت و پهنای باند بهینهسازی شده است. ولی برای ارتباط نقطه با کلاینت از پروتکل ASCII استفاده میشود.
تنظیم Redis Cluster در سیستم محلی
ابتدا باید Redis را بر روی سیستمتان نصب کنید. قبلاً در مورد نصب این ابزار در لینوکس صحبت کرده بودیم.
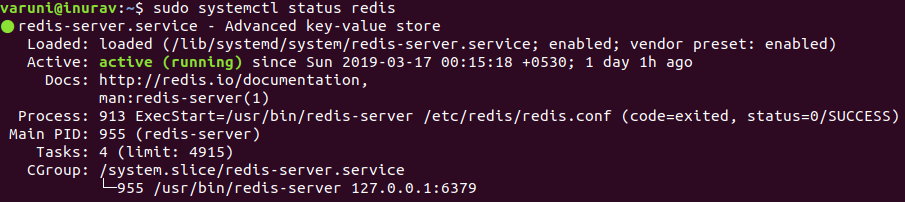
$ sudo apt update $ sudo apt install redis-server $ sudo gedit /etc/redis/redis.conf //open the file and search for "supervised". It is set to No by default. Change it to "systemd" $ sudo systemctl restart redis.service //restart the redis service just in case if it is not started --> sudo systemctl enable redis-server (this should work hopefully! 😊) $ sudo systemctl status redis //check whether the Redis service is running.If it is running successfully, you will get an output like below
حالا موقع بهکارگیری ابزار Redis cluster است. دو روش برای این منظور وجود دارد.
- با ایجاد Redis های خالی در حالت کلاستر.
- با استفاده از اسکریپت create-cluster
روش دوم، سادهتر و سریعتر است. برای این منظور، مراحل زیر را باید انجام دهید.
۱) وارد توزیع Redis خودتان شوید. فولدر “utils” را پیدا کنید. در این فولدر، یک فولدر دیگر با نام “create-cluster” خواهید دید. یک اسکریپت با نام “create-cluster” در این فولدر مشاهده میکنید. این یک اسکریپت ساده است که یک کلاستر ۶ نقطهای با ۳ نقطه اصلی و ۳ نقطه فرعی ایجاد میکند. البته این مقادیر پیشفرض هستند و شما میتواند بنا بر نیازتان، آنها را تغییر دهید.
path: <redis-distribution>/utils/create-cluster
۲) شروع کلاستر
create-cluster start
خروجی

در نتیجه، ۶ نقطه با پورتهای پیشفرض 30001، 30002، 30003، 30004، 30005 و 30006 آغاز به کار میکنند.
همچنین میتوانید عدد پورت پیشفرض را نیز تغییر دهید. برای این منظور، اسکریپت create-cluster را با یک ویرایشگر متنی باز کنید. عبارت PORT=30000 را جستجو کرده و آن را با عدد دلخواهتان جایگزین نمایید.
e.g. PORT=7000 //this will start nodes from port number 7001 onwards
۳) ایجاد کلاستر
create-cluster create
خروجی
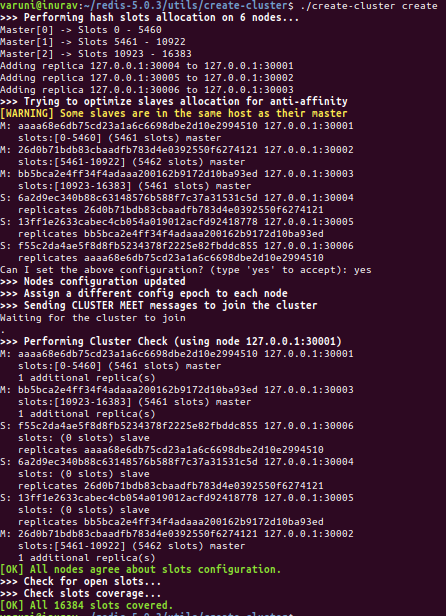
حتماً پس از پیغام ابزار redis-cli برای تأیید الگو، با “yes” پاسخ دهید.
۴) تست کلاستر
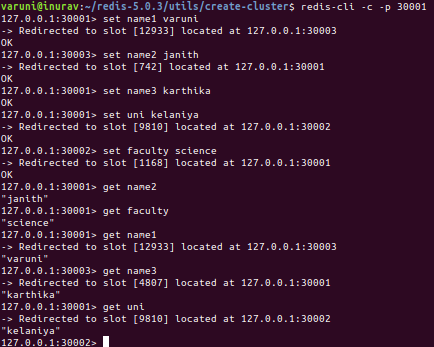
برای این منظور میتوانید از هر کدام از کلاینتهای redis یا redis-cli استفاده کنید. به عنوان مثال، در اینجا داریم:
redis-cli -c -p 30001 set name1 varuni //writing data, using key-value pairs get name1 //reading data, using the key
نکته:
نقاط Redis cluster قادرند تا یک کلاینت را برای دریافت داده به نقطه مناسب هدایت کنند. در همین حال، برخی کلاینتها وجود دارند که میتوانند رابطه انتقال بین hash slot و آدرس نقاط را دریافت کنند و خودشان ارتباط مناسب با نقطه مناسب برقرار نمایند.
۵) توقف کلاستر
create-cluster stop
خروجی

برای مطالعه بیشتر
تفاوت تکرار با شاردینگ
تکرار که با نام «نسخه آینهای» نیز شناخته میشود، تمام دادهها را از نقطه مستر به نقطه فرعی کپی میکند.
شاردینگ نام دیگر پارتیشنبندی یا دستهبندی است. این فرآیند دادهها بر اساس کلید تقسیم میکند.
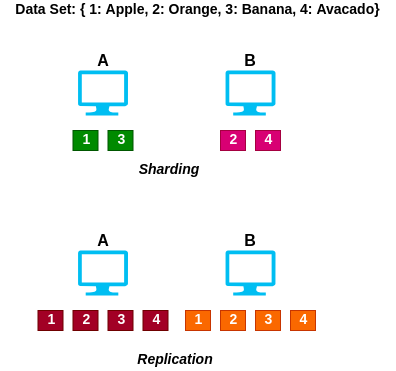
به عنوان مثال، در شاردینگ کلیدهای 1 و 3 در سیستم A ذخیره میشوند و محل ذخیهر کلیدهای 2 و 4 نیز سیستم B است.
داشتن نسخه کپی بهتر است یا کلاسترینگ؟
اگر دادههایتان از فضای RAM موجود در یک سیستم بیشتر بود، بهتر است از ابزار Redis Claster برای تقسیمبندی دادهها در سراسر پایگاههای داده چندگانه استفاده کنید.
در صورتی که مقدار دادههایتان از RAM سیستم کمتر بود، می توانید نسخه اصلی و فرعی تکراری برای جلوگیری از شکست سیستم ایجاد کنید و یک سیستم دیدهبان نیز برای آنها درنظر بگیرید. این دیدهبان سلامت نسخههای اصلی و فرعی را بررسی میکند و در صورتی که نسخه اصلی در دسترس نباشد، نسخه فرعی را معرفی میکند. شما باید حداقل ۳ دیدهبان برای تأیید دسترسی به نقاط داشته باشید.
آیا به حداقل ۳ نقطه اصلی در ابزار Redis cluster نیاز داریم؟
در فرآیند تشخیص مشکل شبکه، حداکثر تعداد نقاط مستر باید به توافق برسند. اگر تنها ۲ نقطه اصلی یا مستر داشته باشید. مثلاً نقاط A و B. در صورتی که B با مشکل روبرو شود، نقطه A نمیتواند بر اساس پروتکل، به یک تصمیم برسد و به یک نقطه سوم C نیاز دارد که عدمدسترسی به نقطه B را تأیید کند.